Памятка по регулярным выражениям
|

1. Введение
Пара слов для тех, кто не совсем в курсе, о чем идет речь. Вы видели когда-нибудь маски имен файлов — всякие там *.html, filename.{txt|csv} и тд? Так вот, регулярные выражения — это те же «маски», только более сложные. В умелых руках регулярные выражения могут быть невероятно мощным инструментом. Так или иначе они используются в 95% моих скриптов.
Многие небезосновательно считают, что регулярные выражения — это скорее самостоятельный язык программирования, чем часть какого-либо языка. Регулярные выражения есть в Perl, PHP, Python, JavaScript, конфигурационных файлах Apache… В зависимости от языка, могут иметь место небольшие различия в синтаксисе регулярных выражений, но основные идеи везде одни и те же.
Поэтому, несмотря на то, что все примеры в заметке написаны на Perl, приведенная информация также пригодится программистам, использующим в своей работе любой другой язык. Например, такой код на PHP:
if(preg_match("/[0123456789]/", $text)) {
// в тексте есть цифры
} else {
// в тексте нет ни одной цифры
}
… и такой — на Perl:
if($text =~ /[0123456789]/) {
# в тексте есть цифры
} else {
# в тексте нет ни одной цифры
}
… делают одно и то же. Как не сложно догадаться по комментариям в коде, здесь идет проверка, содержит ли строка $text хотя бы одну цифру.
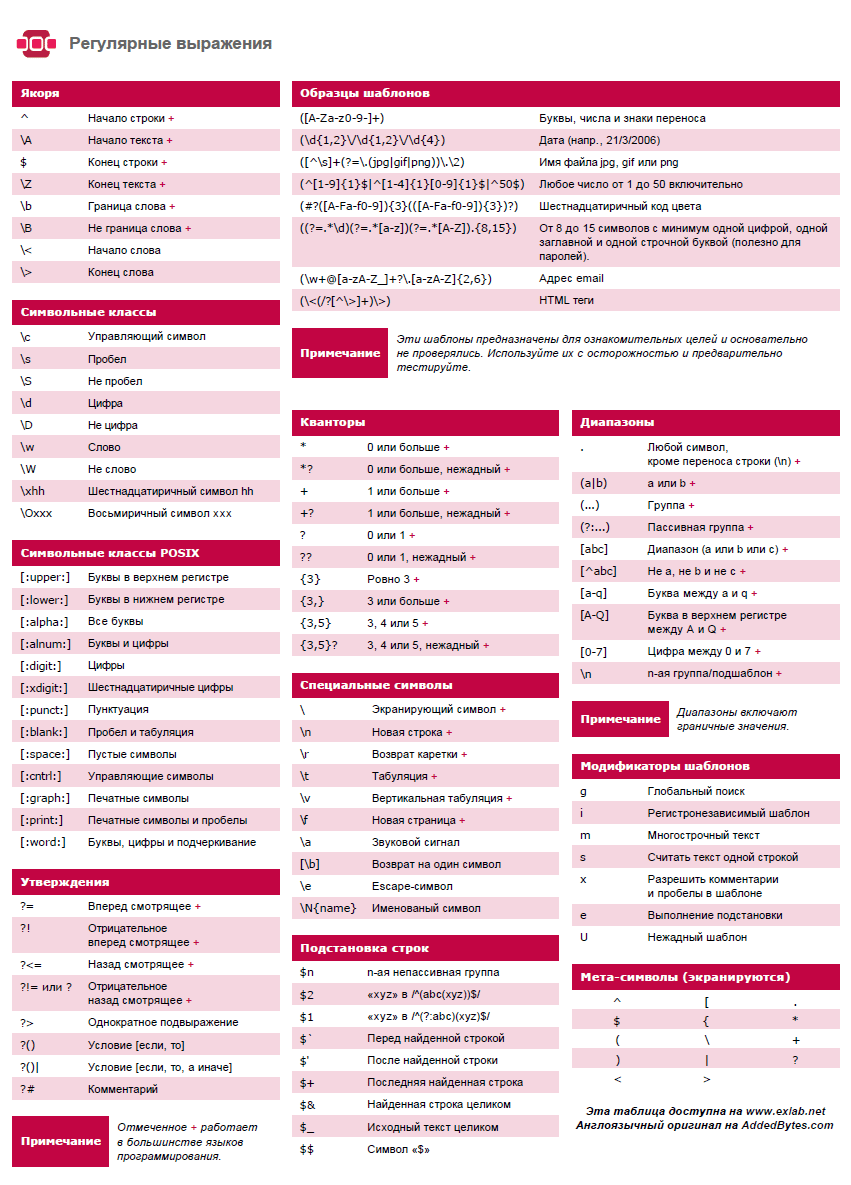
2. Простые примеры
Как всегда, учиться будем на примерах. Квадратные скобки в регулярных выражениях означают «здесь должен быть один из перечисленных символов». Например, приведенному выше выражению [0123456789] соответствует любая строка, содержащая хотя бы одну цифру. Аналогично, выражению [abc] соответствует любая строка, содержащая хотя бы одну из первых трех букв латинского алфавита. Чтобы обозначить любой символ, кроме заданных, используется запись [^abcdef], то есть с символом крышки сразу за открывающейся квадратной скобкой.
Пусть нам нужно проверить, содержит ли строка любой символ латинского алфавита. Перечислять все 26 букв не совсем удобно, правда? Специально для таких случаев в регулярных выражениях можно использовать тире в квадратных скобках для обозначения упорядоченного множества символов. Выражению [a-z] будет соответствовать любая строка, содержащая хотя бы одну строчную букву латинского алфавита. По аналогии, приведенный ранее пример с цифрами можно записать более коротко:
if($text =~ /[0-9]/) {
# в тексте есть цифры
} else {
# в тексте нет ни одной цифры
}
И еще пара примеров:
if($text =~ /[a-z0-9]/) {
# в тексте есть цифры и/или строчные буквы
# подходит: abc, ZZaZZ, ===17
# не подходит: EPIC FAIL, @&#^*!@#
}
if($text =~ /[^0-9]/) {
# в тексте есть символы, отличные от цифр
# подходит: abc, 123abc456, 0x1111111111
# не подходит: 123, 123456, 9999999999
}
if($text =~ /[a-zA-Z]/) {
# в тексте есть буквы латинского алфавита
# подходит: ___Abba___, zyx
# не подходит: 0123, ^_^
}
if($text =~ /[a-fA-F0-9]/) {
# текст содержит цифры и буквы от A до F
# подходит: ***777***, DeadC0de, intel, 0_o
# не подходит: Xor, wiki
}
Усложним задачу. Теперь нам нужно проверить не просто наличие или отсутствие определенных символов, а соответствие строки определенному формату. Вот несколько простых примеров:
if($text =~ /num=[0-9]/) {
# подходит: num=1, some_num=000, bebenum=2(&^*
# не подходит: NUM=1, my_num=-1, num=abc
}
if($text =~ /<img src="[^"]+">/) {
# подходит:
# zzz<img src="logo.png">zzz
# <img src="http://example.ru/logo.png">
# не подходит:
# <img src='logo.png'>
# <img src="logo.png" />
}
Внимательный читатель поинтересуется, что это за знак плюса стоит в последнем регулярном выражении? Этот символ означает «один или более символов, указанных перед этим плюсом». Почти то же самое обозначает символ звездочка — «от нуля до сколько угодно символов, указанных перед звездочкой». Например, выражению A+ будет соответствовать последовательность из одного и более символов A, а выражению [0-9]* — любое количество цифр, в том числе и ни одной.
Иногда количество символов нужно задать точнее. Это можно сделать с помощью фигурных скобок. Например, выражению [0-9]{8} соответствует любая последовательность из ровно восьми цифр, а выражению [a-z]{3,8} — последовательность, содержащая от 3-х до 8-и символов латинского алфавита.
Число на второй позиции можно не указывать. То есть выражение [a-z]{3,} также может иметь место. Оно означает «не менее трех строчных букв латинского алфавита». Выражение {0,} полностью аналогично звездочке, а {1,} — плюсу. Выражение {0,1} можно записать более коротко, используя знак вопроса.
Пример (не самый простой, зато интересный):
if($text =~ /<img src=["']{1}https?[^"']+["']{1} *>/) {
# подходит:
# dfgd<img src="http://example.ru/logo.png">dfgdfg
# <img src='https://null' >
# не подходит:
# <img src="logo.png">
# <img src="http://bebebe'bebebe">
}
Если от этого примера у вас закипают мозги, самое время немного попрактиковаться в регулярных выражениях путем написания тестовых программок. Иначе от дальнейшего прочтения у вас будет каша в голове. Если пока что все понятно, идем дальше.
3. Как выдрать кусок строки?
Символ вертикальной черты (он же «пайп» или просто «палка») в регулярных выражениях означает «или». Например, выражению [a-zA-Z]{20}|[0-9]{25} соответствуют все строки, содержащие 20 символов латинского алфавита или 25 цифр подряд. Обычно этот символ используется совместно с круглыми скобками, предназначенных для группировки частей регулярного выражения. Пример:
if($filename =~ /backup(19|20)[0-9]{2}-[0-9]{2}-[0-9]{2}/) {
# подходит: backup2011-04-01, backup1999-01-13
# не подходит: backup1873-12-12, backup2101-07-07
}
У круглых скобок есть еще одна функция. С их помощью можно выдирать куски соответствующих строк. В PHP результат сохраняется в переменную, указанную третьим аргументом функции preg_match. В Perl совпадения для 1-ой, 2-ой … 9-ой пары скобок сохраняются в переменные $1, $2, …, $9 . Но удобнее использовать такую конструкцию:
if(my ($y, $m, $d) =
$filename =~ /backup([0-9]{4})-([0-9]{2})-([0-9]{2})/) {
print "year = $y, month = $m, day = $d\n";
}
Спрашивается, под каким номером искать совпадение в возвращаемом массиве, если регулярное выражение содержит вложенные скобки? Все просто — совпадения возвращаются в том же порядке, в котором идут открывающиеся скобки. Пример:
my $filename = "./dumps/backup2011-04-01.tgz";
$filename =~ /backup((20|19)[0-9]{2})-([0-9]{2})-([0-9]{2})/;
print "$1, $2, $3, $4\n";
# выведет: 2011, 20, 04, 01
Иногда нам хотелось бы сгруппировать какую-то часть выражения, но не возвращать ее. Для этого сразу за открывающейся скобкой нужно написать последовательность из знака вопроса и двоеточия. Пример:
if(my ($y, $m, $d) =
$filename =~ /backup((?:20|19)[0-9]{2})-([0-9]{2})-([0-9]{2})/) {
print "year = $y, month = $m, day = $d\n";
}
Также за круглыми скобками может следовать вопросительный знак, плюс или звездочка, означающие, что конструкция, указанная в скобках, необязательна, должна повторяться 1+ раз или должна повторяться 0+ раз соответственно. Использование фигурных скобок вслед за круглыми также допустимо.
4. Начало и конец строки
Часто бывает полезным обозначить в регулярном выражение место, где должна начинаться и/или заканчиваться строка. Первое делается с помощью символа крышки в начале выражения, второе — с помощью знака доллара в конце. Примеры:
if($text =~ /^[1-9][0-9]*/) {
# текст, начинающийся с десятичной цифры
# подходит: 3, 801403, 6543bebebe
# не подходит: 0275, -123, abc11111
}
if($text =~ /^0x[0-9a-fA-F]{1,8}$/) {
# шестнадцатеричное число в C-нотации
# подходит: 0x5f3759df, 0xDEADBEEF
# не подходит: 0x1234xxx, xxx0x5678, xxx0x9ABCxxx
}
Не сложно, правда? Обратите внимание, что при проверке полей веб-форм, аргументов функции перед подстановкой их в SQL-запрос и так далее, обязательно следует проверять всю строку, как это сделано в последнем регулярном выражении.
Примечание: Если кого-нибудь интересует, что это за «магические числа» 0x5f3759df и 0xDEADBEEF, обращайтесь к Википедии.
5. Специальные символы
Помимо названных специальных символов следует также особо отметить точку. Она означает любой символ, кроме символа новой строки. Пример использования:
if(my ($name) = $arg =~ /^--name=(.+)$/) {
print "Hello, $name!\n";
}
По умолчанию регулярные выражения производят так называемый жадный разбор. Другими словами, ищутся совпадения максимальной длины. Когда мы используем точку, с этим могут возникнуть проблемы. Например, нам нужно выдрать некоторый текст из сотни HTML-страниц примерно такого содержания:
<span>Text <em>text</em> text</span><span>Source: http://eax.me/</span>
Следующий код вернет нам не то, что хотелось бы:
# в регулярном выражении содержится слэш, поэтому # приходится использовать вместо него другой ограничитель my ($text) = $data =~ m#<span>(.*)</span>#; print $text; # выведет наиболее длинное совпадение: # Text <em>text</em> text</span><span>Source: http://eax.me/
А вот что произойдет, если отключить жадный разбор (внимание на знак вопроса):
my ($text) = $data =~ m#<span>(.*?)</span>#; print $text; # выведет первое совпадение: # Text <em>text</em> text
Да, следующие строки делают одно и то же:
# обычная запись ...
$text =~ /([0-9]{4})-([0-9]{2})-([0-9]{2})/;
# на самом деле - лишь сокращение оператора m//
$text =~ m/([0-9]{4})-([0-9]{2})-([0-9]{2})/;
# вместо слэша можно использовать разные скобочки:
$text =~ m{([0-9]{4})-([0-9]{2})-([0-9]{2})};
$text =~ m<([0-9]{4})-([0-9]{2})-([0-9]{2})>;
$text =~ m[([0-9]{4})-([0-9]{2})-([0-9]{2})];
$text =~ m(([0-9]{4})-([0-9]{2})-([0-9]{2}));
# или даже такие символы:
$text =~ m!([0-9]{4})-([0-9]{2})-([0-9]{2})!;
$text =~ m|([0-9]{4})-([0-9]{2})-([0-9]{2})|;
$text =~ m#([0-9]{4})-([0-9]{2})-([0-9]{2})#;
# а также крышку, кавычки, двоеточие, запятую, точку, ...
Зачем понадобилось столько способов записи регулярных выражений? Представьте, что выражение содержит слэши, точки, запятые и прочие символы, но не содержит восклицательного знака. Тогда, очевидно, мы не можем использовать для обозначения начала и конца регулярного выражения слэши, точки и так далее, зато восклицательный знак — можем.
Часто в регулярных выражениях приходится использовать обратный слэш. Поставленный перед точкой, скобкой, плюсом, крышкой и другими символами, он означает «следующий символ означает именно символ, а не что-то другое». Например, вот как можно определить расширение файла по его имени:
# экранированная обратным слэшем точка # означает именно точку, а не "любой символ" my ($ext) = $fname =~ /\.([a-z0-9]+)$/; print "file name: $fname, extension: $ext\n";
Кроме того, обратный слэш используется в следующих обозначениях:
- \t — обозначает символ табуляции (tab)
- \r и \n — символы возврата каретки (return) и новой строки (new line)
- \xNN — соответствует символу с ASCII кодом NN, например \x41 соответствует заглавной букве A латинского алфавита
- \s — соответствует пробелу (space), табуляции, символу новой строки или символу возврата каретки
- \d — означает любую цифру (digit), а точнее — то, что считается цифрой в Юникоде (см слайд номер 102 в этой презентации)
- \w — означает так называемое «слово» (word), аналог [0-9a-zA-Z_]
В последних трех выражениях запись буквы в верхнем регистре означает отрицание. Например, \D соответствует выражению [^0-9], \W — выражению [^0-9a-zA-Z_], а \S — любому «не пробельному» символу.
Все эти «буквенные» выражения можно использовать внутри квадратных скобок. Например, выражение [a-f\d] полностью эквивалентно [a-f0-9].
Особого внимания заслуживают выражения \b и \B, означающие границу слова (в том же понимании «слова», как и в случае с \w) и отсутствие границы слова соответственно. Например, выражению perl\b соответствует строка «perl rulez!», но не соответствует «perlmonk». С выражением perl\B все с точностью наоборот. Надеюсь, идея ясна.
И еще один пример:
# разбиваем полное имя файла на путь и имя my($path, $fname) = $full_name =~ /^(.*)\/([^\/]+)$/;
Он иллюстрирует использование обратного слэша для экранирования символа, который используется для обозначения границ регулярного выражения. В данном примере это — прямой слэш.
6. Модификаторы
Поведение регулярных выражений можно менять с помощью модификаторов. Например, как вы уже могли заметить, соответствие строки регулярному выражению проверяется с учетом регистра символов. Изменить это поведение можно с помощью модификатора /i (case insensitivity):
# выражение $str =~ s/[a-z]/i; # полностью аналогично $str =~ s/[a-zA-Z]/;
По-умолчанию производится поиск только первого совпадения регулярному выражению. Модификатор /g позволяет осуществить глобальный (global) поиск:
# выдираем из HTML-файла все, что выделено жирным # знак вопроса - для отключения жадного разбора my @words = $html =~ m#<strong>(.*?)</strong>#g; # будьте осторожны при использовании /g в скалярном контексте # подробности здесь: http://koorchik.blogspot.com/2011/07/perl-5.html print "$_\n" for(@words);
Как было сказано выше, точка обозначает любой символ, кроме символа новой строки. Изменить такое поведение можно с помощью модификатора /s:
# выдираем из HTML-файла содержимое статьи, # которое может содержать далеко не одну и не две строчки my ($article) = $html =~ m#<div id="article">(.*?)</div>#s;
Кстати, если в регулярном выражении нужно обозначить «любой символ» без использования модификатора /s, используйте выражение [\d\D]. Оно означает «любой символ, являющийся цифрой, или не являющийся цифрой», то есть вообще любой символ.
Наконец, ничто не мешает использовать несколько модификаторов одновременно:
# выдираем из HTML-файла все, что выделено жирным my @words = $html =~ m#<strong>(.*?)</strong>#gi; # сработает для <strong>, <STRONG> или даже <StRoNg>
Дополнение: Еще полезный модификатор — /o. Он означает «компилировать регулярное выражение только один раз». В некоторых случаях модификатор может существенно ускорить скрипт. Правда, я не уверен, что он поддерживается где-то, кроме как в Perl.
7. Заключение
Данная заметка не претендует на полноту. Однако в ней перечислены почти все возможности регулярных выражений, которыми мне когда-либо приходилось пользоваться. Я специально умолчал о замене с помощью регулярных выражений (оператор s/// в Perl), модификаторе /e, работе с юникодом и, возможно, нескольких других моментах.
Заметка и так получилась раза в два больше, чем я планировал. Так что, о названных вещах я напишу как-нибудь в другой раз. В качестве источника дополнительной информации я бы рекомендовал man perlrequick (быстрое введение в регулярные выражения) и man perlre (более подробное описание сабжа).